Scaling ECS Fargate like Lambda

#Scaling ECS Fargate like Lambda
In this post, we explore how fast ECS Fargate can scale compared to Lambda. We use a real world example of processing messages from an SQS queue.
Spoiler alert: nothing can beat AWS Lambda for scaling. But we can’t always run everything on Lambda. This post explores how to get the best out of ECS Fargate.
The code is available here: https://github.com/rehanvdm/sqs-lambda-ecs-fargate-scaling
Use these experiments and results as a reference for your own testing only. Many factors and small adjustments can affect the results. We made some assumptions and kept the testing environment as consistent as possible.
📺 Prefer video? Watch the full walkthrough instead of reading! 📺
#Table of Contents
- Scenario: Lambda sets the target 🎯
- Success criteria
- Napkin math to calculate ECS targets
- Experiment 1: Batch size 1
- Experiment 2: Batch size 10 and aggressive scaling
- Experiment 3: Batch size 10, aggressive scaling and custom metric
- Addendum: Testing and evaluating method
- Conclusion
#Scenario: Lambda sets the target 🎯
We are creating a scenario where Lambda has been working well but now we need to move to ECS Fargate. We will start by working backwards from the Lambda implementation and then try to match its performance with ECS Fargate.
The Lambda is experiencing the following traffic patterns:
- Average traffic is around 100M requests per month (about 40 RPS).
- Weekday working hours steady state is around 75 RPS (about 4.5k RPM or 6.5M RPD). Nights and weekends are around 20 RPS.
- The system experiences about 50 bursts (1 or 2 per weekday) of around 300k requests spread over 10 minutes (about 500 RPS).
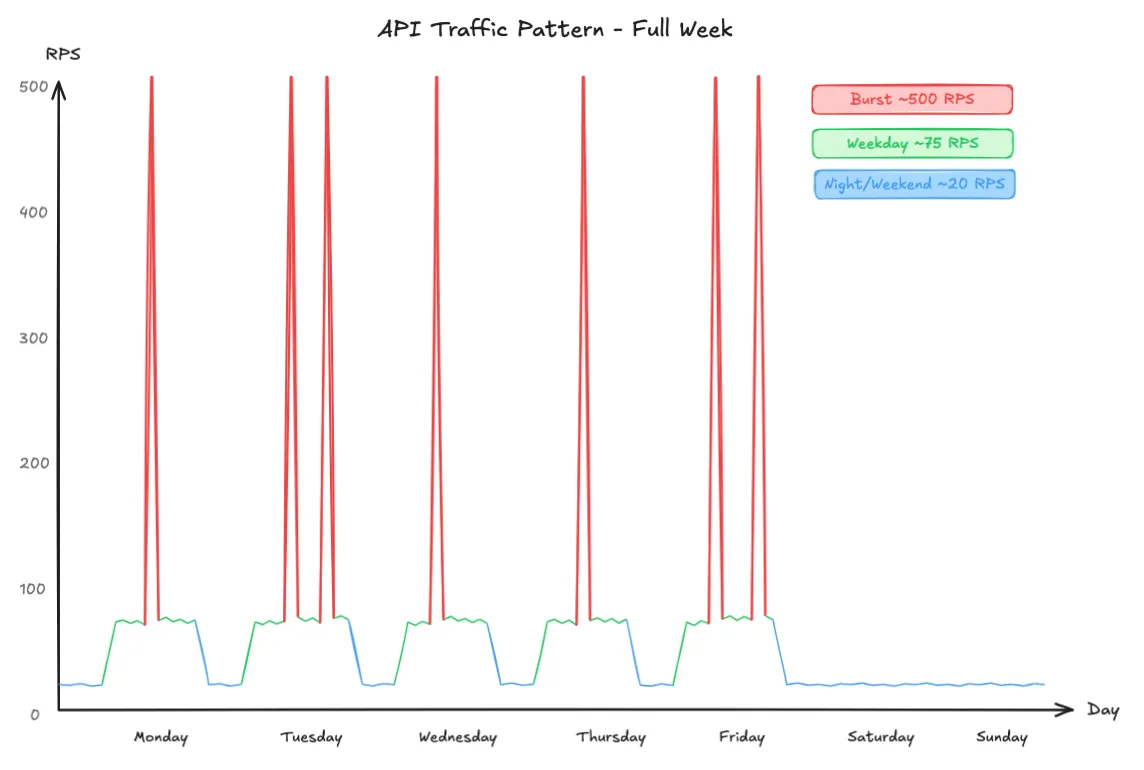
We are only going to focus on handling the burst. The steady state is easily handled by both Lambda and ECS Fargate. Each message simulates some work being done by sleeping for 200ms.
#Success criteria
In our scenario, we want to see how close we can get to Lambda’s performance with ECS Fargate. Our Lambda benchmark can process the messages with no queue forming.
In this blog, we are not actually using a queue for its intended purpose as a buffer to handle bursts. We are using it to test the scaling capabilities of ECS Fargate and see how close we can get to Lambda’s performance.
1. Age of the oldest message on the queue must be 0
This is the time since the oldest message in the queue was received. It indicates how quickly the system is
processing messages. The lower the better. Ideally we always want this to be close to 0, meaning each message is
processed as soon as it arrives.
2. The number of visible messages on the queue must be 0
This is the number of messages that are currently available for processing. A high number of visible messages
indicates that the system is not processing messages fast enough to keep up with the incoming traffic.
3. Time to process the burst must be the same as the time it takes for messages to be enqueued
This is the total time it takes to process all messages in the burst. The lower the better. Ideally we want this to
be close to the time it takes for messages to be enqueued, meaning the system is processing messages as fast as they
arrive.
#Napkin math to calculate ECS targets
Working backwards from Lambda costs to determine our ECS Fargate configuration. We will use the same memory configuration (512MB) for ECS and then adjust the number of tasks and scaling configuration to match the performance of Lambda while staying within the same cost.
#Lambda baseline (512MB, 202ms, us-east-1)
- Single burst: $0.57 (
(300k × ($0.20 / 1M)) + (0.5 GB × 0.202s × 300k × $0.0000166667/GB-s)) - Monthly (@100M requests): $188.33 (
(100M × ($0.20 / 1M)) + (0.5 GB × 0.202s × 100M × $0.0000166667/GB-s))
#ECS Fargate (512MB, 0.25 vCPU)
- Cost per task: $9.07/month (
$0.0126/hour × 24 × 30) - Monthly tasks (running 24/7): 20 (
$188.33 / $9.07) 🎯
This means that if we run 20 tasks 24/7, we will be within the same cost as Lambda for the same number of requests. But our usage is bursty, not constant. We make the assumption that per day the average utilization is 40% of the peak.
Peak capacity = 20 tasks / 0.40 ≈ 50 tasksTarget scaling: 10 to 50 tasks
- Min (10): Steady state baseline
- Max (50): Burst capacity within budget
- Avg (~20): Expected monthly average
#Experiment 1: Batch size 1
Our first experiment just tests the waters. We set the batch size to 1 so that each message is processed individually.
Key observations:
| Metric | Lambda | ECS Fargate |
|---|---|---|
| Time to first scale | a few seconds | 4 minutes |
| Age of the oldest Message | 23 seconds | 22 minutes + |
| Max number of visible messages | 14,900 | 292,000 |
| Time to process | 8 minutes | a long time |
#Lambda
For Lambda this means 1 invocation per message. This experiment demonstrates how fast Lambda can scale to handle the burst. With a max concurrency of 300 (not reached, max was 280 at the start then around 225), Lambda processed 38,000 messages per minute at steady state. The queue never backed up. Messages were consumed as fast as they arrived.
Code Highlight: Lambda simplicity
consumerLambda.addEventSource(
new SqsEventSource(this.queue, {
batchSize: 1,
reportBatchItemFailures: true,
maxConcurrency: 300,
})
);#ECS Fargate
This experiment was done before the napkin math, so we were not sure how many tasks we would need to handle the burst. It was just testing the waters. This just goes to show how easy and effortlessly Lambda scales.
ECS Fargate will also process one message per task at a time. Starting at 1 as the minimum and scaling to a maximum of 10 tasks, this means only 10 messages will be processed concurrently, compared to the 225 messages of Lambda. Our step scaling was too conservative, scaling too slowly.
The metric we scaled on queue.metricApproximateNumberOfMessagesVisible() is the maximum
over 5 minutes, which takes too long.
Code Highlight: Conservative step scaling
const scaling = service.autoScaleTaskCount({
minCapacity: 1,
maxCapacity: 10,
});
scaling.scaleOnMetric(name("queue-depth-scaling"), {
metric: this.queue.metricApproximateNumberOfMessagesVisible(),
scalingSteps: [
{ upper: 0, change: -1 }, // There are 0 messages visible reduce task by 1
{ lower: 100, change: +1 }, // More than 100 visible add 1 task
{ lower: 500, change: +2 }, // More than 500 visible add 2 tasks
{ lower: 1000, change: +3 }, // More than 1000 visible add 3 tasks
],
cooldown: Duration.seconds(60),
});#Experiment 2: Batch size 10 and aggressive scaling
In this experiment we set the batch size for both to 10 and process these messages in parallel. We also set ECS Fargate to scale more aggressively with the correct number of tasks as calculated in the napkin math to handle the burst.
Key observations:
| Metric | Lambda | ECS Fargate |
|---|---|---|
| Time to first scale | a few seconds | 3 minutes |
| Age of the oldest Message | 0 | 59 seconds |
| Max number of visible messages | 1 | 23,500 |
| Time to process | 7 minutes | 7 minutes |
#Lambda
Lambda now scales slower because messages are being processed faster than with batch size 1. In the first experiment, we saw that it overscaled at the beginning. The Lambda processing time is now 1 minute faster with batch size 10 compared to batch size 1. It could probably have gone faster but the ESM SQS poller decided to not invoke it faster.
We get near perfect results with this experiment.
#ECS Fargate
ECS Fargate takes 3 minutes to scale up compared to Lambda which is instant. We are down from 4 to 5 minutes from experiment 1. If you don’t have enough ECS Fargate steady state capacity, you could see a big backlog for messages in the first 3 minutes as we do here. A small backlog accumulated about 8% of the messages and we can see that the processing spikes near the start of the burst as the newly scaled out tasks help process the backlog.
This is a good result. We are able to process the burst in 7 minutes, which is the same as Lambda. But 23k messages accumulated in the queue of which the oldest message is 59 seconds, which is not ideal.
Code Highlight: Aggressive step scaling
const scaling = service.autoScaleTaskCount({
minCapacity: 10,
maxCapacity: 50,
});
scaling.scaleOnMetric(name("queue-depth-scaling"), {
metric: this.queue.metricApproximateNumberOfMessagesVisible({
statistic: "Maximum",
period: Duration.seconds(30), // Will only be reported every 60 seconds, but we are hopeful
}),
scalingSteps: [
{ upper: 100, change: -5 }, // There are less than 100 messages visible reduce task by 5
{ lower: 100, upper: 1000, change: 0 }, // Between 100 to 1k visible hold steady, no scaling
{ lower: 1000, upper: 5000, change: +5 }, // More than 1k to 5k visible add 5 task
{ lower: 5000, upper: 10000, change: +10 }, // More than 5k to 10k visible add 10 task
{ lower: 10000, change: +20 }, // More than 10k visible add 20 tasks
],
cooldown: Duration.seconds(20),
});#Experiment 3: Batch size 10, aggressive scaling and custom metric
In the previous experiment we noticed that ECS Fargate still takes 3 minutes before it even starts to scale. The contributing factors are:
- CloudWatch metric publication delay (~1 minute): Time it takes for metrics to be published and become visible in CloudWatch. Not officially documented, just observed.
- SQS eventual consistency (~1 minute): The
ApproximateNumberOfMessagesVisiblemetric is deliberately delayed to provide higher confidence in the number. This is SQS being cautious about eventual consistency.
We can’t fix the CloudWatch publication delay. But we can publish our own metric faster.
Key observations:
| Metric | Lambda | ECS Fargate |
|---|---|---|
| Time to first scale | a few seconds | 2 minutes |
| Age of the oldest Message | 0 | 27 seconds |
| Max number of visible messages | 0 | 13,800 |
| Time to process | 7 minutes | 7 minutes |
#Lambda
Stays about the same as in experiment 2, we did not change anything for Lambda.
#ECS Fargate
We cannot change the CloudWatch metric publication delay, but we can publish the SQS metric faster. To reduce this time
we publish a fine grained metric that reports the ApproximateNumberOfMessagesVisible every 15 seconds with a Lambda
function.
This allows us to react faster to the burst, we are able to start scaling after 2 minutes, which is a 1 minute improvement. We are unfortunately limited by the CloudWatch metric publication delay, and the time it takes for a scaled task to be provisioned and start processing messages.
We reduced the max number of visible messages to 13,800, which is an improvement from 23,500 in experiment 2. The age of the oldest message is also reduced to 27 seconds down from 59 seconds in experiment 2. This is a better result and most likely the best we can do with ECS Fargate.
Code Highlight: Custom metric for scaling
The code for the Lambda that publishes the custom metric can be seen here: https://github.com/rehanvdm/sqs-lambda-ecs-fargate-scaling/blob/develop/app/backend/queue-detailed-metric-publisher/src/index.ts
const scaling = service.autoScaleTaskCount({
minCapacity: 10,
maxCapacity: 50,
});
scaling.scaleOnMetric(name("queue-depth-scaling"), {
metric: new cloudwatch.Metric({
namespace: "SQS/Detailed",
metricName: "ApproximateNumberOfMessages",
dimensionsMap: {
QueueName: this.queue.queueName,
},
statistic: "Maximum",
period: Duration.seconds(30), // Reporting every 15 seconds, we have at least 1-2 data points
}),
scalingSteps: [
{ upper: 100, change: -5 }, // There are less than 100 messages visible reduce task by 5
{ lower: 100, upper: 1000, change: 0 }, // Between 100 to 1k visible hold steady, no scaling
{ lower: 1000, upper: 5000, change: +5 }, // More than 1k to 5k visible add 5 task
{ lower: 5000, upper: 10000, change: +10 }, // More than 5k to 10k visible add 10 task
{ lower: 10000, change: +20 }, // More than 10k visible add 20 tasks
],
cooldown: Duration.seconds(20),
});#Addendum: Testing and evaluating method
The code for this blog and experiments is available here: https://github.com/rehanvdm/sqs-lambda-ecs-fargate-scaling
The messages are generated by a single lambda function that is invoked manually. This runs for about 7 to 8 minutes and generates 300k messages, messages are sent to both queues in parallel. This is a repeatable process that allows us to test the scaling of ECS Fargate and Lambda under the same conditions.
The Lambda and ECS Fargate code simulates processing by waiting for 200ms. They process messages in parallel, so a batch of 1 and a batch of 10 will take the same time to process.
Charts have the same axes (time range and maximum y value) so that they can visually be compared with each other. Charts are generated from CloudWatch metrics.
There are a lot of small adjustments and improvements that can be made, but they will all depend on specific use cases and requirements. A few that come to mind are:
- Don’t use step scaling at all, this relies on a CloudWatch metric that is delayed, just scale the ECS number of tasks directly from the Lambda function that publishes the custom metric. This should reduce the time to first scale, by 1 minute, there might be edge cases that you need to handle, and you will need to maintain this code instead of relying on AWS to do it for you.
- You can pipeline the reading operation of the SQS messages in the ECS Fargate container code, but this will increase the time to process each message as seen by SQS and adds complexity.
- Our ECS Fargate tasks are over provisioned for the burst. We provisioned our ECS Fargate to cost the same as Lambda, defeating one of the primary reasons for using ECS Fargate over Lambda. In the real world, you might want to provision fewer tasks and accept a longer processing time for the burst
The goal of this blog is to show how fast ECS Fargate can scale compared to Lambda with a real world example of processing messages from an SQS queue. We had to impose constraints to make the testing and evaluation possible, but the results should be used as reference for your own testing and implementation.
#Conclusion
| Metric | Lambda | ECS Fargate | ECS Fargate custom metric |
|---|---|---|---|
| Time to first scale | a few seconds | 3 minutes | 2 minutes |
| Age of the oldest Message | 0 | 59 seconds | 27 seconds |
| Max number of visible messages | 1 | 23,500 | 13,800 |
| Time to process | 7 minutes | 7 minutes | 7 minutes |
For this specific scenario, ECS Fargate can relatively keep up with our Lambda performance. ECS Fargate takes 2-3 minutes to scale up compared to Lambda which is instant.
This will break down at much bigger bursts. ECS Fargate will not be able to scale as fast. See a good deep dive on a comparison for scaling containers on AWS here: https://www.vladionescu.me/posts/scaling-containers-on-aws-in-2022/
There will always be a backlog of messages when using ECS Fargate to process a burst. We are limited by the CloudWatch metric publication delay and the time it takes for a scaled task to be provisioned and start processing messages.
This can be mitigated with aggressive scaling and using a custom metric taking the scaling into your own hands. It can get close to Lambda speed, but it will never be as fast as the near instant scaling of Lambda.