Should you use a Lambda Monolith, aka Lambdalith, for your API?

This post looks at some arguments for and against a monolith Lambda API function (aka Lambdalith) compared to single-purpose Lambda functions per API route. It challenges “best practices” and argues that a monolith Lambda function is better in many cases when it comes to an API.
IMPORTANT. This post is only applicable to the API facing Lambda function. For everything else use single-purpose functions. This is a controversial topic and my personal opinion backed by years of experience.
#TL;DR
The argument to limit the blast radius on a per route level by default is too fine-grained, adds bloat and optimizes too early. The boundary of the blast radius should be on the whole API/service level, just as it is and always has been for traditional software.
Use a Lambalith if you are not using any advance features of AWS REST API Gateway and you want the highest level of portability to other AWS gateways or compute layer. There are also many escape hatches to fill some of the promises that single-purpose functions offer.
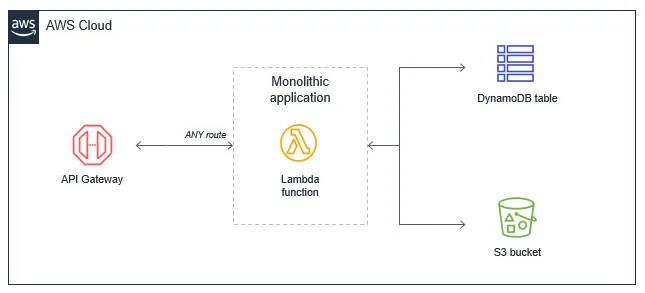
#The case FOR a Lambda Monolith (Lambdalith)
- By proxying all the requests to a single Lambda it results in fewer resources to be provisioned and thus faster deployments.
- Resource count/stack size stays constant and does not grow with the number of routes.
- Less cold starts (frequency), warm lambda containers are reused more often. The fewer Lambda functions you have, the fewer cold starts you will have.
- Least privilege permissions are still applied, but to an API level. The blast radius moves to an API/service level, not a route level.
- Reserved concurrency is applied to the whole API, not per route. Reserved concurrency is a scarce account level commodity and it can not be applied accurately on a route level.
- Provisioned concurrency can be applied economically to a single Lambda function, instead of having to over provision and scale multiple Lambda functions for each individual route.
- Logs to a single CloudWatch log group:
- Fewer Metric Filters need to be created to alarm on things like soft errors.
- Fewer Log Subscription Filters and Alarms to create, maintain and monitor.
- Increased portability, it does not lock you into using AWS API REST Gateway. Since we are not making use of advance features like; API keys, rate limiting, routing, validation, etc. It is easy to change the API gateway to AWS HTTP APIs or an ALB. The compute layer can also easily be swapped from Lambda to ECS.
- Fits traditional API design, many existing frameworks can be used.
- Less code duplication, shared code between routes stays within the repo.
- Less context switching, and cognitive load compared to single-purpose functions because shared code is in the same repo.
- Easier maintenance to shared code and tests.
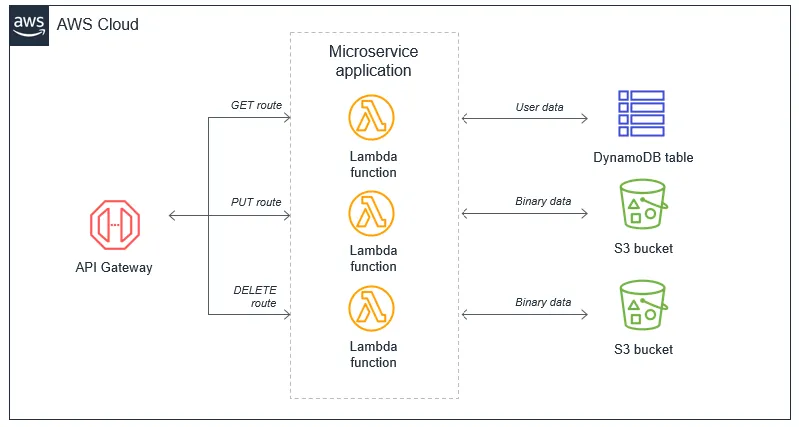
#The case AGAINST a Lambda Monolith (Lambdalith)
- Longer cold starts, because the Lambda function is bigger.
- Loose fine-grained control over:
- Permissions
- Timeouts
- Environment variables
- Memory
#The in-between
For me, using a Lambdalith for your API has the highest ROI. There are multiple escape hatches to fill some of the promises that single-purpose functions offer.
Let’s look at an example where you have a route that is used for generating invoices.
This route requires more memory and maybe a longer timeout than the rest of the API. You don’t want to increase the memory
and timeout for the whole API because it might be more expensive, you only want more power for a specific route.
To accommodate this, create another route specifically for /invoice alongside
the existing /{proxy} route. Then by giving each route there own Lambda function (with the exact same code), you can
provide the invoice Lambda with more memory and a higher timeout than the default proxy Lambda.
Reusing the same codebase between the routes has some advantages like keeping the tests exactly the same. But you can of course optimize this further by splitting the codebase between these two routes so that the proxy route never has to load the heavy packages to create invoices. This can be a physical split of code between folders or can be done using some smart compile/build time logic (for TS, ESBuild supports this little-known feature). We can also still consider this a monolith, which means we can easily share code between these routes.
Cold starts affect only a very small portion of your total invokes, tail latencies are important but average latencies are
more important and should be optimized first. Compile time tools like ESBuild that bundle your code into a single file
instead of shipping the whole node_modules folder, reduces package size and cold starts.
With a consistent log format across all routes, CloudWatchLog Insights makes it possible to extract any information from any route from the Lambda’s single Log Group.
#AWS best practices
Let’s start by breaking down some of the arguments from AWS on the best practice method arguing for single-purpose Lambda functions. I will be screen-grabbing and quoting from this doc in the AWS documentation.
#Monolith disadvantages
AWS argues that you should only use a Lambdalith when you “lift and shift” an application. Then later you must break it up to single-purpose functions.
- Package size: the Lambda function may be much larger because it contains all possible code for all paths, which makes it slower for the Lambda service to download and run.
✅ This is true, the more routes you handle, the more code will be in your Lambda function and the longer the cold start. BUT cold starts affect only a very small portion of your total invokes, yes p99.99 is important but p50 is more important.
What’s always been so surprising is that internally at Amazon teams spend far less time on this than I see external customers obsessing over it.
— Chris Munns (@chrismunns) October 2, 2023
Ppl are here worrying about their <.25% of invokes when PC exists for a reason, while ignoring slow DB queries and poor caching
- Hard to enforce least privilege: the function’s IAM role must allow permissions to all resources needed for all paths, making the permissions very broad. Many paths in the functional monolith do not need all the permissions that have been granted.
🚫 Let’s consider the old traditional server-full API approach. You would not create a server or container for each route, just to enforce least privilege, would you? So why do this for the API Lambda? The answer is that you can and the decision doesn’t carry the same financial burden because *true serverless is pay-for-what-you-use.
On top of that, the majority of routes all do similar things, interact with the same services and will thus need similar permissions. Let’s consider that there is a security incident and that only 1 of your single-purpose lambdas is compromised. It would be naive to think that you “limited the blast radius” and therefore dismiss that the whole system (other single purpose API functions) could potentially be compromised as well.
So it makes little to no difference whether you specify many small fine-grained permissions for single-purpose functions VS a combined permission set for the whole API. As long as you continue to practice the principle of least privilege when writing IAM permission.
- Harder to upgrade: in a production system, any upgrades to the single function are more risky and could cause the entire application to stop working. Upgrading a single path in the Lambda function is an upgrade to the entire function.
🚫 Using the word “Riskier” instead of “Harder” might be what they are going for here. The idea is to limit the blast radius which is a valid argument but does not make sense given some context.
If one of your routes fails, then you will only know about it when that route gets traffic. This is because this argument assumes no code is shared between single-purpose functions, which is a fallacy. Because of this, I find it scarier to update just a single route’s code and assume that the rest of the API will still be working as expected.
To minimize the blast radius, you should instead consider creating a different API/service based on design requirements when there is shared code. This is because the risk will always be present on individual routes if code is shared within an API thus moving the boundary of the blast radius from a route level to an APIs/service level is the better choice.
- Harder to maintain: it’s more difficult to have multiple developers working on the service since it’s a monolithic code repository. It also increases the cognitive burden on developers and makes it harder to create appropriate test coverage for code.
🚫 It is easier to maintain since you:
- Don’t have to write duplicate code and can reuse code between routes
- Enforce the same flow structure for all routes, ex: catching errors and returning consistent error responses
- Have all business logic in a single place
- Tests all in one place, including shared code
So on the contrary, having everything together reduces cognitive load and context switching. BUT there is a limit to this and APIs need to be broken up and grouped by responsibilities into their own services when the project gets too large. Conway’s law will also come into play as soon as you start to have multiple services and teams. I wrote a blog post on this topic below.
- Harder to reuse code: typically, it can be harder to separate reusable libraries from monoliths, making code reuse more difficult. As you develop and support more projects, this can make it harder to support the code and scale your team’s velocity.
🚫 Now the big one, reusing code is by far easier in a monolith.
Consider the scenario for patching an error in a library that is used in all your single-purpose functions:
- You have to publish shared code into packages that need to be used by all of your routes
- You would have to context switch, make the change in the library, merge, publish the package
- Then context switch again and update the version in each of your 100’s of routes to use the new version
- Then you need to test and deploy all the 100’s of routes
So to make a blanket statement that it is harder to reuse code in a monolith is wrong. There might come a point where the project grows very large and making a change to a single function will require refactoring in many other places. But this same problem exists if you split your codebase across packages, it is now just a distributed problem, which is far worse for velocity.
- Harder to test: as the lines of code increase, it becomes harder to unit all the possible combinations of inputs and entry points in the codebase. It’s generally easier to implement unit testing for smaller services with less code.
🚫 The complexity and number of tests stay the same, regardless of using a monolith or single-purpose functions. The number of routes and thus tests will be the same. You will actually be able to write less shared code tests for a monolith. An example of this is testing for CORS, you can write a single test for CORS in a monolith if you have defined an “allow all” policy, but will have to write a test for each route in a single-purpose architecture.
#Single purpose advantages
Compared to the monolith, AWS argues that single-purpose functions are better because:
- Package sizes can be optimized for only the code needed for a single task, which helps make the function more performant, and may reduce running cost. Package size is a determinant of cold start latency, which is covered in chapter 6.
✅ As mentioned before, this is true, smaller packages will always be more performant and cost-effective.
- IAM roles can be scoped to precisely the access needed by the microservice, making it easier to enforce the principles of least privilege. In controlling the blast radius, using IAM roles this way can give your application a stronger security posture.
🚫 The argument for least privilege should not be applied at a route level but the boundary of the blast radius should be moved to an API/service level.
- Easier to upgrade: you can apply upgrades at a microservice level without impacting the entire workload. Upgrades occur at the functional level, not at the application level, and you can implement canary releases to control the rollout.
🚫 I believe “Less Risk in upgrading” will be better suited here. The argument is that you can upgrade a single route without affecting the rest of the API. This is true but only if you have no shared code between routes. But I have seen no API that does not have shared code between routes (maybe I just do serverless APIs wong 🤷).
The argument of canary releases is not a benefit when applied at a route level. It only adds resources and time to the deployment as you now have to define many extra resources to support this per route.
- Easier to maintain: adding new features is usually easier when working with a single small service than a monolithic with significant coupling. Frequently, you implement features by adding new Lambda functions without modifying existing code.
🚫 Adding new features might be easier, but you will most likely be using shared code and if not, then you are forced to copy and duplicate. Or make shared packages that you can pull into your single-purpose functions. This argument is explored in more depth in the previous sections.
I am also sure that you will be modifying existing code MUCH more than adding new lambda functions.
- Easier to reuse code: when you have specialized functions that perform a single task, it’s often easier to copy these across multiple projects. Building a library of generic specialized functions can help accelerate development in future projects.
🚫 I have already covered this in the previous section, but to reiterate, I can never advocate for duplicating code. This just creates tech debt, which, if incurred must be paid off later and will slow velocity. The only correct way to share code per route level Lambda functions, is to create a standalone package and pull it in. This has its own set of advantages and issues as mentioned before.
- Easier to test: unit testing is easier when there are few lines of code and the range of potential inputs for a function is smaller.
🚫 The complexity and number of stay stays the same, regardless of using a monolith or single-purpose functions.
- Lower cognitive load for developers since each development team has a smaller surface area of the application to understand. This can help accelerate onboarding for new developers.
🚫 There will be more context switching between packages of shared code and cognitive load when working with single-purpose functions.
#Conclusion
The argument to limit the blast radius on a per route level by default is too fine-grained, adds bloat and optimizes too early. The boundary of the blast radius should be on the whole API/service level, just as it is and always has been for traditional software.
Use a Lambalith if you are not using any advance features of AWS REST API Gateway and you want the highest level of portability to other AWS gateways or compute layer. There are also many escape hatches to fill some of the promises that single-purpose functions offer.